Dataset Overview
Contents
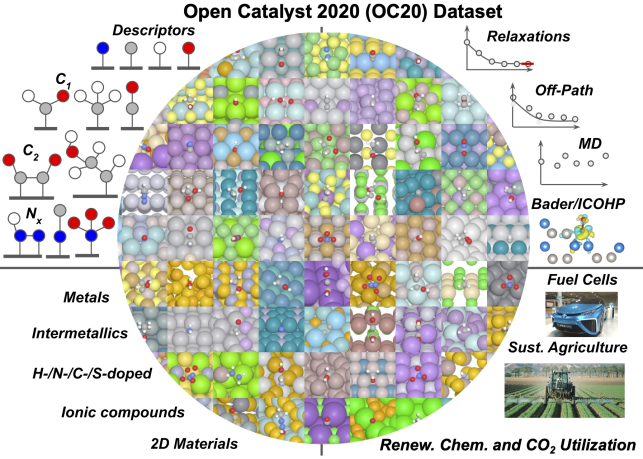
Dataset Overview#
The Open Catalyst 2020 Dataset (OC20) will be used throughout this tutorial. More details can be found here and the corresponding paper. Data is stored in PyTorch Geometric Data objects and stored in LMDB files. For each task we include several sized training splits. Validation/Test splits are broken into several subsplits: In Domain (ID), Out of Domain Adsorbate (OOD-Ads), Out of Domain Catalyast (OOD-Cat) and Out of Domain Adsorbate and Catalyst (OOD-Both). Split sizes are summarized below:
Train
S2EF - 200k, 2M, 20M, 134M(All)
IS2RE/IS2RS - 10k, 100k, 460k(All)
Val/Test
S2EF - ~1M across all subsplits
IS2RE/IS2RS - ~25k across all splits
Tutorial Use#
For the sake of this tutorial we provide much smaller splits (100 train, 20 val for all tasks) to allow users to easily store, train, and predict across the various tasks. Please refer here for details on how to download the full datasets for general use.